
超越跑分,我们该如何评价AI大模型的智商?

随着越来越多的模型性能接近GPT-4,几个主要的评测手段都已经无法进行有效区分。
1, MMLU,分数均80+分,已缺乏区分度。
2, MT-Bench,裁判员是GPT-4,能力不足以分辨模型之间的能力差别。
3, Arena Elo:主要是普通对话类任务,让Elo分数受到和人类对齐程度的极大影响,且问题难度不足以分辨这个级别的模型。
尚存的评测方法是人类或者自动使用未见过的数据集进行高难度评测,低难度的任务缺乏区分度。
目前在高难度评测中,GPT-4依然是最好的那个。
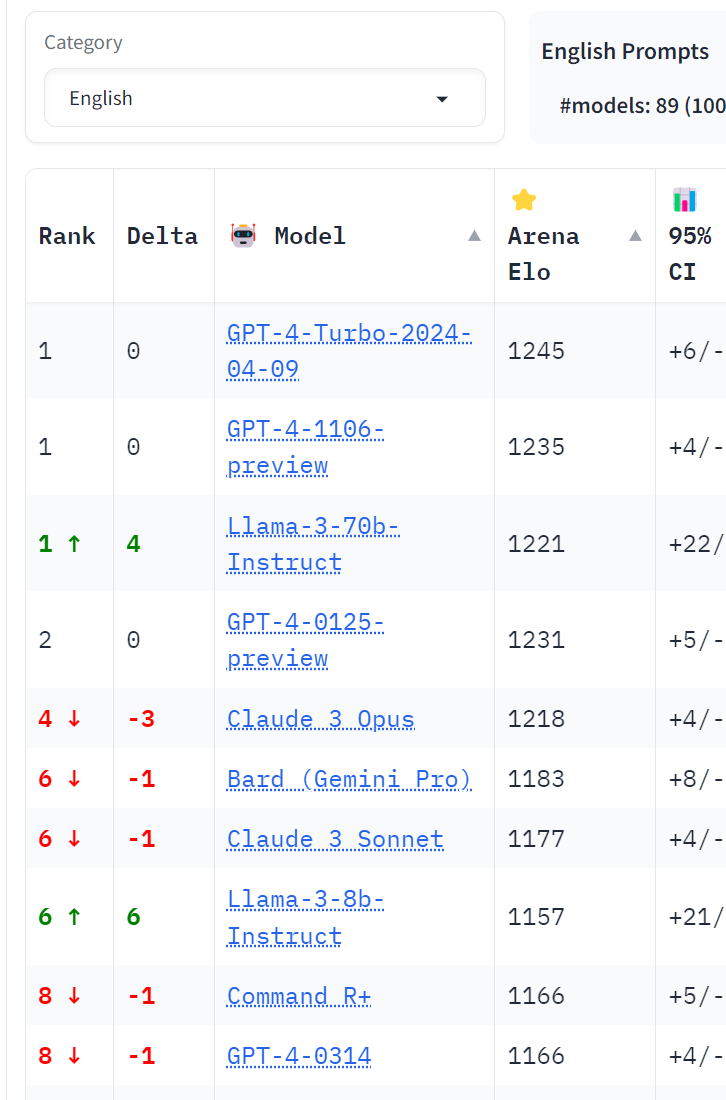
这个领域挺有趣的,就是我们到底怎么评判这么多大模型孰强孰弱? 还是其实本就没有一个客观的标准?包括去年我们和里屋社区的小伙伴们一起开始做MNBVC的时候,我们还想过有没有可能我们出一个标准出来(后来知道这个想法是不自量力了)。
不过,这些跑分标准都号称权威,但是从我们做应用的实际角度来看,就是本身这些评测标准或者打分标准,和LLM一样本身也处在刚刚起步的阶段,这些评分标准并不能真的完全客观的代表大模型的逻辑思维能力,也就是我们常说的“智商”,叫IQ或者就叫做AI的东西。
现在很多AI大模型能够通过一些技巧在一些跑分评测中拿到好成绩,不是坏事,是有意义的。但是,过去两年我通过做AI应用,以及通过做MNBVC项目接触到很多大模型业内专业人士,逐步的认识到,你大模型跑分再好,如果最终解决实际问题上的能力差别在那里摆着的话,我不是还是没法用你吗?
我也承认任何个别问题就是个别问题,不代表所有。但是个别问题有个别问题的代表性。
因此,我说的情况就是,同样的个别问题,GPT-4o比其他模型(包括OpenAI的其他模型)表现更好。
而且在GPT-4o发布之前,我在里屋也就说过的,答对一个已知答案的问题其实也说明不了太多问题。有太多可能。但是在都是答错的回答里面,去看这个大模型输出的文字的语言组织,解题思路,解题方法…… 这些是我们判断今天的所谓AI的智商的标准。
看看他们有多像人嘛。

我们从去年 ChatGPT-3.5 的时代就开始整理了一些很有意思的,很有代表性的测试题。这里也分享给大家,大家可以用这些题去测试一下你见过的这些大模型,从你自己的角度看看这些大模型的智商到底如何?
1,时区问题。
美国中部时间4月21日上午12点是中国广州的什么时间?
这是一个形式上很简单的问题。逻辑点也很简单,就是美国有夏令时,以及时差导致的日期区别。看起来很简单,但是这个问题GPT3.5和很多国产大模型目前还不能准确的理解这个问题并且给出正确的解答。
(这个问题,今天2024年5有21日,GPT-4o能答对,GPT3.5和GPT4,以及通义千问2.5,Gemini1.5 ,都无法给出正确答案)
2,齿轮问题。
三个齿轮成星形排列,且两两咬合,这个齿轮组能够转动吗?
这个问题可以继续扩充至多个单数齿轮构成的环形齿轮组。持续增加齿轮数量,就能看出AI的逻辑推理能力。
(这个看起来简单吧,在今天不如GPT-4的大模型,都回答错误。)
3,啤酒问题
有一个店卖啤酒,啤酒2元一瓶。除此之外,店长规定,四个瓶盖可以换一瓶。2个空瓶也可以换一瓶。请问用10元钱,可以喝几瓶啤酒?
这个问题属于那种小学生的题目。很绕,但是不需要什么技巧。就是需要一点逻辑能力和一些记忆力。大家可以试试,现在各家大模型都不太容易处理好这个问题,但是各家的大模型在这个问题上的表现也是不同的。说白了就是错也是错的有不同的档次的呢。
(目前只有GPT-4o能够给出清晰的解题思路并且得出正确答案。)
4,积分问题
现在已知用户操作有三个选择,选择A消耗15积分。选择B消耗99积分。选择C消耗150积分。有一个用户有250个积分。他进行了5次操作之后,还剩下7个积分。那么请问,该用户这5次操作应该都进行了哪些选择?
这种题目不在于有多难,其实关键反而是它很简单。
在《线性代数》或高等代数中有详细讨论。在初中阶段,如果所含三个三元一次方程互不矛盾,且没有等价的(一个变形后可得另一个),则方程组有唯一一组解。如果仅有两个方程,一般有无穷多组解。
几何意义是:三个平面既不平行,也不重合,必定有一个公共点,有两个平行时无公共点,有两个重合时有无数的公共点。
因此这个题目能列出两个方程的三元一次方程组乍一看是不能解的。这也是用这个例子做测试,大多数AI会解题错误的原因。
但是,这个题有趣就在于,人类通过人眼一看,很容易就可以基本上预测【C=0】,因此这个三元一次方程组立刻就变成二元一次方程组了,变得可解,并且可以验算出来这就是唯一正确的解:
A=3,B=2,C=0
GPT3.5是无法得出正确答案的。Gemini1.0也不行。
GPT4 和 Gemini 1.5 都有可能得出正确答案,按时需要对问题更多的引导。这很明显了提现了AI模型的代差所体现的AI 逻辑思维能力水准的差异。
前不久发布的 GPT-4o 能够直接完美的解决这个问题,着实令我意外。
……
当然,一个题目永远都是个案,说明不了太多。而且去年AI大模型刚开始火遍全球的时候我就说过,AI的价值绝不是我们绞尽脑汁问几个刁钻的问题或者脑筋急转弯,看看AI是答对了还是答错了。
关键是我们要看这个AI到底有多少逻辑思维能力,能够多大程度上真的在脑力劳动上帮助我们人类分忧解难。
这篇Blog里列出来的4个典型中文问题,大家都可以去各个大模型上自己试试看,看看即使是不简单的论答案的对错的前提下,各个大模型对于这些逻辑问题的理解能力和解答的方法有什么差异。
有什么自己判断大模型逻辑能力的私人祖传偏方吗?不如这个帖子里交流一下。
说不定,大家还能群策群力,给世界贡献一个全新的AI智商测试标准呢?!
